
Search engines are one of society’s primary gateways to information and people, but they are also conduits for misinformation. Similar to problematic social media algorithms, search engines learn to serve you what you and others have clicked on before. Because people are drawn to the sensational, this dance between algorithms and human nature can foster the spread of misinformation.
Search engine companies, like most online services, make money not only by selling ads, but also by tracking users and selling their data through real-time bidding on it. People are often led to misinformation by their desire for sensational and entertaining news as well as information that is either controversial or confirms their views. One study found that more popular YouTube videos about diabetes are less likely to have medically valid information than less popular videos on the subject, for instance.
Ad-driven search engines, like social media platforms, are designed to reward clicking on enticing links because it helps the search companies boost their business metrics. As a researcher who studies the search and recommendation systems, I and my colleagues show that this dangerous combination of corporate profit motive and individual susceptibility makes the problem difficult to fix.
How search results go wrong
When you click on a search result, the search algorithm learns that the link you clicked is relevant for your search query. This is called relevance feedback. This feedback helps the search engine give higher weight to that link for that query in the future. If enough people click on that link enough times, thus giving strong relevance feedback, that website starts coming up higher in search results for that and related queries.
People are more likely to click on links shown up higher on the search results list. This creates a positive feedback loop – the higher a website shows up, the more the clicks, and that in turn makes that website move higher or keep it higher. Search engine optimization techniques use this knowledge to increase the visibility of websites.
There are two aspects to this misinformation problem: how a search algorithm is evaluated and how humans react to headlines, titles and snippets. Search engines, like most online services, are judged using an array of metrics, one of which is user engagement. It is in the search engine companies’ best interest to give you things that you want to read, watch or simply click. Therefore, as a search engine or any recommendation system creates a list of items to present, it calculates the likelihood that you’ll click on the items.
Traditionally, this was meant to bring out the information that would be most relevant. However, the notion of relevance has gotten fuzzy because people have been using search to find entertaining search results as well as truly relevant information.
Imagine you are looking for a piano tuner. If someone shows you a video of a cat playing a piano, would you click on it? Many would, even if that has nothing to do with piano tuning. The search service feels validated with positive relevance feedback and learns that it is OK to show a cat playing a piano when people search for piano tuners.
In fact, it is even better than showing the relevant results in many cases. People like watching funny cat videos, and the search system gets more clicks and user engagement.
This might seem harmless. So what if people get distracted from time to time and click on results that aren’t relevant to the search query? The problem is that people are drawn to exciting images and sensational headlines. They tend to click on conspiracy theories and sensationalized news, not just cats playing piano, and do so more than clicking on real news or relevant information.
Famous but fake spiders
In 2018, searches for “new deadly spider” spiked on Google following a Facebook post that claimed a new deadly spider killed several people in multiple states. My colleagues and I analyzed the top 100 results from Google search for “new deadly spider” during the first week of this trending query.
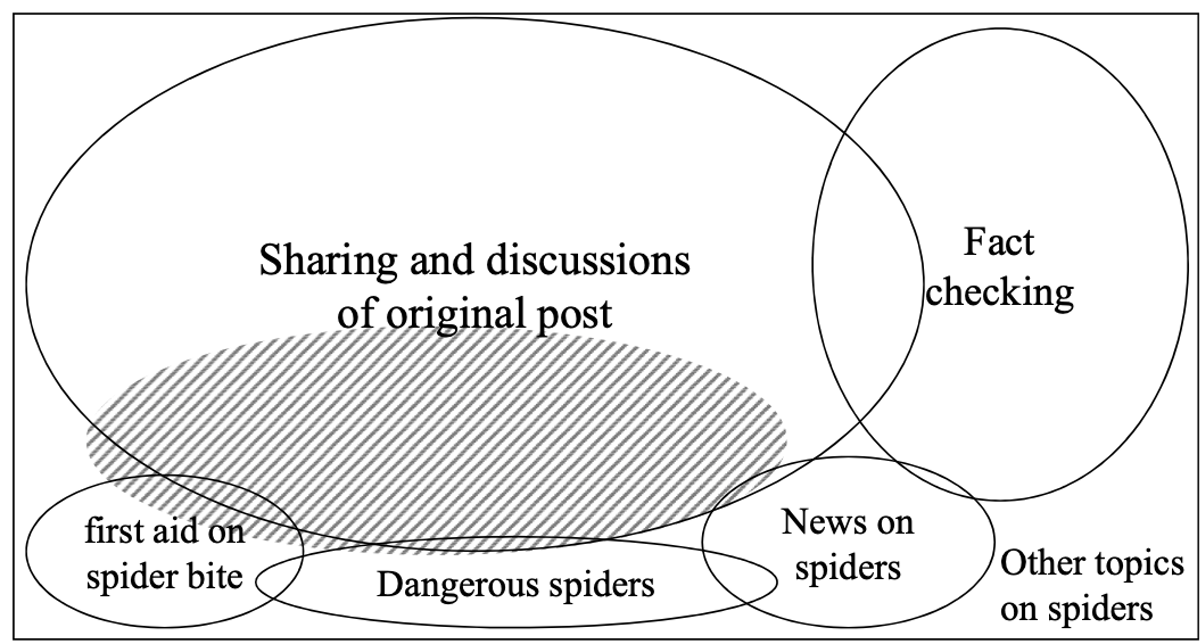
It turned out this story was fake, but people searching for it were largely exposed to misinformation related to the original fake post. As people continued clicking and sharing that misinformation, Google continued serving those pages at the top of the search results.
This pattern of thrilling and unverified stories emerging and people clicking on them continues, with people apparently either being unconcerned with the truth or believing that if a trusted service such as Google Search is showing these stories to them then the stories must be true. More recently, a disproven report claiming China let the coronavirus leak from a lab gained traction on search engines because of this vicious cycle.
Spot the misinformation
To test how well people discriminate between accurate information and misinformation, we designed a simple game called “Google Or Not.” This online game shows two sets of results for the same query. The objective is simple – pick the set that is reliable, trustworthy or most relevant.
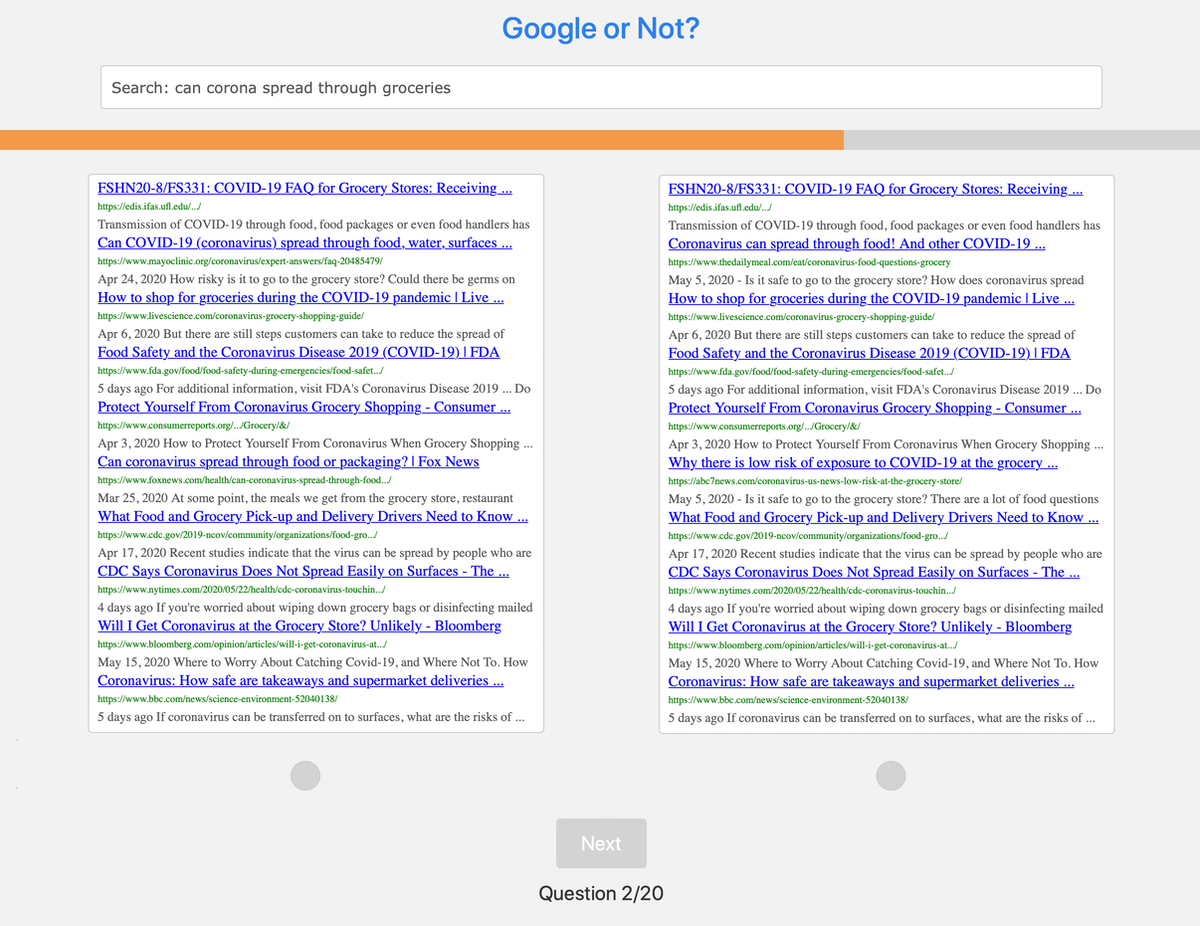
One of these two sets has one or two results that are either verified and labeled as misinformation or a debunked story. We made the game available publicly and advertised through various social media channels. Overall, we collected 2,100 responses from over 30 countries.
When we analyzed the results, we found that about half the time people mistakenly picked as trustworthy the set with one or two misinformation results. Our experiments with hundreds of other users over many iterations have resulted in similar findings. In other words, about half the time people are picking results that contain conspiracy theories and fake news. As more people pick these inaccurate and misleading results, the search engines learn that that’s what people want.
Questions of Big Tech regulation and self-regulation aside, it’s important for people to understand how these systems work and how they make money. Otherwise market economies and people’s natural inclination to be attracted to eye-catching links will keep the vicious cycle going.
- is Associate Professor of Information Science, University of Washington
- This article first appeared on The Conversation


